The use of logic as a ``programming'' language, or at least as a meaning to mechanically
express and manipulate reasoning, has been implicit since its creation [33].
Nevertheless, it was not until the creation of Prolog, thanks to the brilliant intuitions
of Colmeraur and Kowalski [16], that ``logic'' became ``logic programming''. Key
issue in this evolution step is the understanding that a subset of first order logic,
namely Horn Clause Logic, could be sufficiently expressive for practical programming
purposes and still efficiently implementable![]() .
.
Even though reasonably fast interpreters for Prolog, like the C-Prolog realized by Pereira, Damas, and Byrd had been developed, a myth of ``logic programming = slow implementations'' developed and still survives. Only with the advent of Prolog compilers this myth started declining and at present extremely fast implementations are available--capable on some specific programs of beating state-of-the-art C compilers [90].
The real breakthrough is represented by the introduction of the Warren Abstract Machine (WAM) [116, 2, 37], which has become a standard de-facto for the implementation of Prolog and Logic Programming languages.
The WAM defines an abstract architecture whose instruction set allows an easy mapping from Prolog source code and to it is sufficiently low-level to allow an efficient emulation and/or translation to native machine code.
The WAM is a stack-based architecture, sharing some similarities with imperative languages
implementation schemes (e.g., use of call/return instructions, use of frames for
maintaining procedure's local environment), but extended in order to support the
features peculiar to Logic Programming, namely unification and
backtracking![]() .
The major data areas of the WAM are (as shown in
figure 3):
.
The major data areas of the WAM are (as shown in
figure 3):
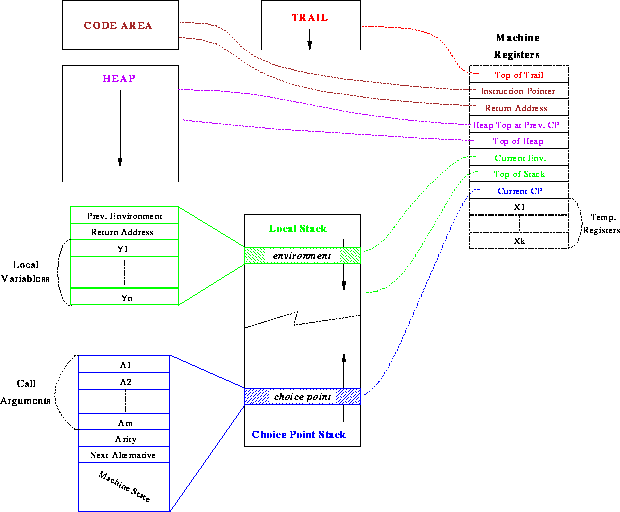
Figure 3: Organization of the WAM
Being a dynamically typed language, Prolog requires a type information to be associated with each data object. In the WAM, Prolog terms are represented as tagged words. Each word is composed by a tag, identifying the type of the object (e.g. atom, list, etc.), and by a value (e.g. atom name, pointer to the first molecule of a list, etc.).