Richardson [101] discusses how to determine semantic relatedness using the information extracted from MRD's, specifically incorporating relations extracted using Vanderwende's [116] techniques. All the relations extracted from the same definition are first grouped into the same structure and then these structures are inverted to make backward links explicit in the network. To alleviate problems due to ambiguous words, paths are generally restricted to occur within a single structure; extended paths are possible, but there is a penalty based on the frequency of the joining word. The highest weight path between two words can be used to determine the relatedness of the words. This path weight combines the weight of individual relations (detailed next) by multiplying the weights, which are conditional probabilities given the occurrence of the preceding word in the path.
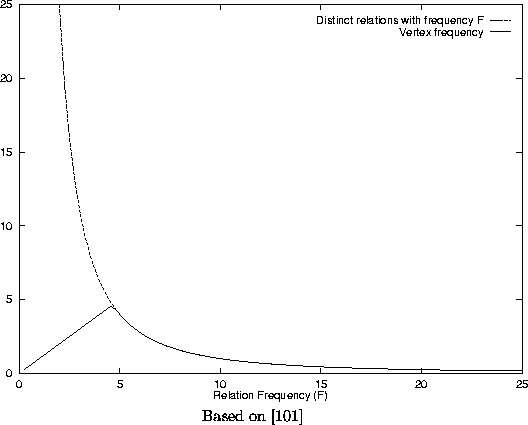
A novel procedure is used for weighting the relationships, using notions derived from the weighting of terms in information retrieval by term frequency (TF) and inverse document frequency (IDF), which is referred to as TF*IDF. Specifically, a term's weight is proportional to its overall frequency but inversely proportional to the number of documents it occurs in. He uses semantic relations in place of terms, so the frequencies are those for the relational triples. In addition, in place of TF*IDF, he uses a technique, called averaged vertex probability, that combines frequency scaling and probability smoothing. Frequent relations are scaled back whenever the frequency exceeds that of the vertex of a Zipfian hyperbolic function8 (see Figure 3). The idea is to favor those relations that occur with moderate frequency, defined as the vertex point of the Zipfian frequency plot. Because the frequency of the relations is skewed due to lack of high-frequency function words and large number of low-frequency relations in dictionary definitions, the hyperbolic function used to model the Zipfian relationship is based on the counts of distinct relations at particular frequencies (i.e., plotting count vs. frequency instead of frequency vs. rank). Smoothing is accomplished by averaging the vertex probability for the entire relation ( Pv(w1, R1, w2)) with the vertex probability for the pairing of the relational type and object ( Pv(R1, w2|R1)).
Richardson [101] also developed a novel procedure for determining similarity of words. Recall that the path weight can be used for determining relatedness, but this doesn't distinguish general relatedness from similarity. To handle this, patterns of relations that imply similarity are learned by tabulating those patterns that occur often between words that are known to be very similar (and not just related), based on a thesaurus. The similarity of new words pairs is calculated by averaging the probabilities of the path patterns found in the highest-weighted paths between the words.