There have been a few studies that have used lexical associations derived from corpus analysis in structural disambiguation. Hindle and Rooth [56] were the first to demonstrate the basic technique. They show how to induce lexical associations from simple syntactic relationships (e.g., verb/object) extracted using somewhat shallow parsing, in combination with a few heuristics for resolving ambiguous relationships. These associations can be considered as conditional probabilities that a particular preposition is attached to the noun or verb, given that the latter is present. Attachment is resolved by selecting the case with the higher association. Evaluation was performed on 1000 random cases from the AP newswire, showing that the approach improves much over just using right association, a common heuristic. In addition, comparison versus information derived from a dictionary (COBUILD), shows that this corpus-based approach fares better.
To train the system, they first
applied a part-of-speech tagger and a shallow parser to a 13 million
word newswire corpus and then extracted triples of the form
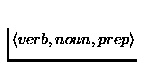 from the parses, where either the
verb or the noun might be empty. Next, heuristics were applied to
associate the preposition with the verb or noun, and the results were
tabulated to produce
from the parses, where either the
verb or the noun might be empty. Next, heuristics were applied to
associate the preposition with the verb or noun, and the results were
tabulated to produce
 and
and
 bigram frequency counts. (Thus, this is
an instance of unsupervised learning, since it doesn't require human
annotations defining examples of the classification being performed.)
bigram frequency counts. (Thus, this is
an instance of unsupervised learning, since it doesn't require human
annotations defining examples of the classification being performed.)
To decide on the attachment for test data, the POS tagging and parsing
are performed as above, along with the extraction of the triples. But
then, instead of using the heuristics on each ambiguous triple
(i.e., those with both verb and noun non-empty), the bigram
frequencies are used in a log-likelihood ratio test:3
 is estimated by
freq(verb,prep)/TotalFreq and likewise for the noun attachment
probability. A positive score favors verb attachment, and a negative
one favors the noun attachment; a score of zero implies insufficient
information to decide on the attachment.
is estimated by
freq(verb,prep)/TotalFreq and likewise for the noun attachment
probability. A positive score favors verb attachment, and a negative
one favors the noun attachment; a score of zero implies insufficient
information to decide on the attachment.
Basili et al. [9] show how the same type of disambiguation can be achieved using selectional restrictions that are semi-automatically acquired from corpus statistics. These selectional restrictions form the basis for their lexicons that are tuned to particular subdomains, in their case, a legal domain, a business domain, and a remote sensing (satellite images) domain. Some important observations are that these selectional restrictions are much different in each domain, and that, in some cases, this information cannot be inferred from conventional dictionary definitions. They define semantic expectation as the probability that a pair of concepts occurs in a given relationship. This is similar in spirit to Resnik's [100] selectional association measure (see below), although they consider more than just verb-object relationships.
The main drawback to this approach is that it requires manual effort
to assign the high-level concepts to the entries in the lexicon. In
addition, it relies upon a core set of selectional restrictions at the
conceptual level that a human must determine as being relevant
(ideally a linguist). However, once this has been done, the rest of
the process is automatic, that is, the determination of the selection
restrictions for particular words.
An experiment in deciding prepositional attachment shows how this
method improves over an extension to Hindle and Rooth's
[56]. See Table
3. They use information gain (
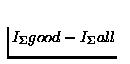 )
as a measure of the task complexity: this indicates
the number of bits needed to represent the reduction in the certainty
that is provided by the classification.
)
as a measure of the task complexity: this indicates
the number of bits needed to represent the reduction in the certainty
that is provided by the classification.
The table shows that semantic expectation (SE), incorporating the selectional restrictions semi-automatically acquired, performs better than lexical association (LA). In addition, the task for SE is slightly more complicated, as indicated by the higher information gain.
| ||||||||||||||||||
Building upon this basic framework for determining verb
subcategorizations, Basili et al. [8] show how
verbs can be hierarchically clustered into classes.
In line with the notion of cue validity, the classification is based
on maximizing the extent to which categories are associated with
different attributes.
Grishman and Steering
[48,49] have also
extracted relational triples from parsed corpora. They use these to
define selectional patterns. The initial work
[48] concentrated on the extraction and
generalization of the triples, using manually developed word classes
from earlier work. The steps in this approach are as follows:

They experimented with various ways for handling the triples due to
multiple parses and for evaluating the results. In one case, they
showed that the performance on selecting parses based on the triples
is better than manually selected parses (as compared to the Penn
Treebank standard parses).
Their later work [49] experimented with
automatically deriving the word classes. To do this, a confusion
matrix is computed, which shows the probability each word can be
used in the same context as the others, taken individually. This is
computed as follows:
![]()
This uses the relation and the relational object (wj) as the context.
A large value of
PC(wi|wi') suggests that wi is ``selectionally
(semantically) acceptable'' in contexts that wi' appears in. Then,
the frequencies for the triples are generalized (smoothed) by averaging the
frequencies for similar words:
![]()
where
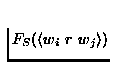 is the smoothed frequency for the triple.
Evaluations revealed that this smoothing can be used to significantly
increase the recall on identifying valid relational triples.
is the smoothed frequency for the triple.
Evaluations revealed that this smoothing can be used to significantly
increase the recall on identifying valid relational triples.
In addition to analyzing large corpora of the same language, there have been several projects that have used bilingual corpora of the same text in different languages, for examples transcripts of the Canadian parliament (Hansards) in French and English [18]. Once the sentences have been aligned, fairly accurate lexical associations can be made between synonymous words in the two languages [44]. This has the advantage of producing a quick and dirty translation lexicon tuned to a particular corpus. It also has found use in lexical ambiguity resolution, since an ambiguous word might be consistently aligned with different unambiguous words in the other language. This type of approach might be helpful in a potential future extension of applying the techniques for extracting finer sense distinctions to definition glosses of bilingual dictionaries (e.g., the extended definitions provided in cases of lexical gaps).
Resnik [100] has done some influential work on combining statistical approaches with more traditional knowledge-based approaches. For instance, he defines a measure based on information content for the semantic similarity of nouns that uses the WordNet hierarchy along with frequency statistics for each synset. These statistics are estimated from the corpus frequency of all the words subsumed by that synset. This is particularly relevant for the proposed work, as it will serve as one of the methods for determining semantic relatedness against which the differentia-extraction technique will be compared.
Resnik's technique relies on the use of WordNet synsets to define the
classes over which frequency statistics are maintained. This is done
to avoid the data sparsity problem associated with statistical
inference at the word level. A benefit of doing this is that the
classes provide an abstraction that facilitates comparison. For
instance, he defines selectional preference profiles for verbs by
tabulating the distribution of the classes for the verbal subjects and
objects. The degree to which verbs select for their arguments can
summarized by a measure called the selectional preference
strength, which is the relative entropy of the distribution for the
conditional probability of the classes given the verb compared to the
distribution of the prior probabilities for the classes
[100]:
The 1993 SIGLEX Workshop [13] emphasized corpus techniques specifically for acquiring lexical knowledge. Some of the techniques rely solely on corpus analysis. For instance, Aone and McKee [5] use heuristics for deciding on the high-level verbal situation type based on the degrees to which the corpus instances are transitive and have animate subjects. These situation types (e.g., caused-process) determine the basic predicate argument structure of the verbs. Also, idiosyncratic properties of the verbs are acquired through the use of mutual information co-occurrence checks.
Grefenstette [46] compares two knowledge-poor techniques for deriving notions of semantic similarity. The evaluation is novel in not requiring hand-coded similarity ratings and in not basing the result on application performance. Instead, a similarity relationship is considered valid if the words occur together in some Roget category. The baseline technique is co-occurrence of words in a window around the target word. The other technique uses shallow parsing to extract syntactic relationships involving the target word. The latter works better in general for high-frequency terms, but it is not as good for infrequent ones. Some of the other techniques incorporate existing lexical resources. For instance, Hearst and Schütze [51] show how to refine the WordNet taxonomy with domain-specific terms. This uses Schütze's WordSpace algorithm which computes a reduced-dimension co-occurrence matrix for tokens of 4 letter sequences from the text4. For a given word in WordSpace, its associated WordNet synset is calculated by finding the one containing the most number of the words in a 20-word nearest neighborhood in WordSpace. Poznanski and Sanfilippo [94] describe a way to extract semantically-tagged subcategorization frames from bracketted corpora, specifically Penn Treebank, using the thesaural and grammatical information in Longman's Lexicon of Contemporary English (LLOCE). This works by extracting the verbal frames, replacing words by their thesaural categories, merging similar frames, and then using the grammatical codes in LLOCE to filter out categories which don't license the particular frame. In other words, this is using LLOCE to convert the word-based subcategorization instances extracted from the Penn Treebank into a class-based form. These still would need to be postprocessed to produce a list of the most common frames. Then to make the work more comparable to Resnik [100] or Basili et al. [9], conditional probability distributions for the various verbal arguments would need to be derived.
Lauer [70] has defined a model for assigning probabilities to meaning representations in a compositional manner. The effect of context is handled by the change in the (prior) probabilities for the concepts. This is illustrated with a simple 1st-order predicate predicate calculus presentation. The mapping of the semantic representation into a syntactic representation is described in detail. For practical reasons, this mapping must be simple, since the source of (unsupervised training) data will be in a form more closer to the syntactic representation.
Two main applications of meaning representations theory are described: first, a syntactic application of the approach (like most current statistical language learning approaches) that selects the most probable bracketing for a N-N-N compound (i.e., [[N N] N] vs. [N [N N]]); second, a novel semantic approach for paraphrasing noun-noun compounds (via prepositional phrases). Unlike the adjacency approach that computes probabilities based on grammatical relatedness, the dependency approach computes probabilities based on conceptual relatedness. For instance, to decide whether a left-bracketing over a right-bracketing is likely for N1-N2-N3, the adjacency approach would just consider the relatedness of (N1, N2) vs. (N2, N3), that is immediate adjacency. In contrast, the conceptual approach considered (N1, N2) vs. (N1, N3), which is at the level of the modification.
A common corpus used in computational linguistics is the Penn Treebank [76]. It consists of parse-tree annotations for a one million word subset of the Wall Street Journal 1989 corpus, along with similar annotations for the Brown corpus. Of particular interest is that the second release of the Penn Treebank [77] includes semantic role tags in their parse tree annotations. The main relations covered are direction, manner, location, purpose, and temporality. The earlier parse tree annotations from the Wall Street Journal corpus were revised and extended, yielding over 35,000 of these semantic role annotations.