Smith and Medin [111] present an in-depth comparison of the three main approaches to representing categories (from the perspective of cognitive psychology): the classical view uses necessary and sufficient properties to describe all members in the category; the probabilistic view uses a descriptive representation incorporating probabilities that members have particular properties; and, the exemplar view uses descriptions in the form of typical members.
The classical view has worked best for geometric concepts because it is straightforward to determine the defining properties for the concepts. But it fails to account for the use of nonnecessary features during categorization. It also doesn't account for a wide range of typicality effects that Rosch [103] and several others have noted, such as faster categorization for typical members. The probabilistic view dispenses with defining properties in favor of a summary description based on features or dimensions describing attributes which are true of members to varying extents. Each feature describe an attribute and is associated with a value indicating the salience for the concept. Comparison is based on a summed feature weight. Alternatively, attributes can be represented as dimensions along which different concepts vary. In this case the concept value for each dimension is an average of the members. Comparison is based on a distance metric (usually of the concept taken as a unit). The main problem with the probabilistic view is providing constraints on what can serve as features or dimensions. The exemplar view dispenses with having a single summary description for all members of a concept, instead using comparisons to prototypes that describe typical members. A main drawback with this view is determining constraints on which members can become prototypes. Smith and Medin conclude that, although both the probabilistic and exemplar views overcome empirical shortcomings of the classical view (e.g., typicality effects), neither is likely to be adequate taken alone.
Rosch [103,102] developed the family
resemblance theory of categorization. Her research highlighted the use
of distinctive features as well as common features in
categorization. One important finding is that natural
categories1
are generally organized so as to maximize the similarity within a
class and minimize the similarity across classes.
In effect, categorization relies on distinctive features through the
use of cue validities, which refers to the degree to which a
feature is associated with a particular category compared to the
association with contrasting categories. In probabilistic terms, cue
validity is the conditional probability of a class given a feature:
[111]:
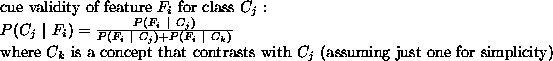
Medin et al. [78] defend similarity against the claim that it is too vacuous to serve as a useful principle for categorization. They show that once the respects are decided (as in ``similarity with respect to ...''), the role of similarity is well-defined. Specifically, similarity is not a fixed process but varies depending on what is being compared: an important part of this process is the alignment of features to be used for the comparison, according to the salient characteristics of the base term (the Y in ``X are like Y''), which leads to asymmetry in the comparison.
It will be seen later that computational accounts of similarity are often symmetrical, especially when using statistical techniques, as in the use of mutual information [101]. These approaches sacrifice psychological validity for simplicity.
Another interesting aspect of the work by Medin et al. [78] is the results of one of the experiments: for certain perceptual categorization tasks, distinctive features are given more weight than common ones. They indicate that this agrees with earlier work by Tversky. This supports the emphasis on cue validities in the work discussed above [111,103]. As described later, Basili et al. [8] incorporate cue validities in their verb clustering algorithm; and, Richardson [101] indirectly supports this by weighting the relations to favor those that occur moderately in a lexical network.