CS575, Artificial Intelligence II
Spring 1999
Assignment 3: Decision Trees
Object
To understand the techniques behind the standard techniques for generating decision
trees automatically from data sets of attribute values. To use standard software, based on
the C5.0 series.
Domain
We will use recognition of handwritten characters as the domain. The task will be to
distinguish handwritten versions of a single character from other characters and/or
images.
Procedure
 Create raw handwritten characters on the supplied grids. Below is
a sample of a few cells from the grid. The first three are positive examples; the last is
a negative example.
Create raw handwritten characters on the supplied grids. Below is
a sample of a few cells from the grid. The first three are positive examples; the last is
a negative example.
Submit the grids for scanning (at 300 pixels per inch). A raw image file will be
returned to you. It will be a bitmap image in which black pixels are represented by
ansunet bit (a 0) and white pixels by an unset bit (a 1). You can then read the raw image
into a program to extract the bitmaps for each character. The extraction technique will
involve a 'histogram' method, i.e. counting black pixels in each row and column. The
crosses at the grid points will be about 30 pixels across, and the lines will be 4 or 5
pixels wide. A histogram of one column of 15 cells will then look like the chart below.
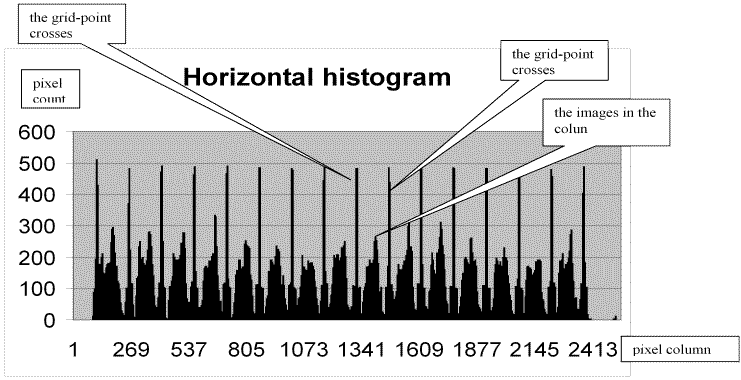
A zero count will indicate white space (the whole column), and by doing the same for the
rows of the image, each character in each cell can be isolated.
Save each character from each cell as a separate image file, or at least in a way so
that each character can be analyzed. Make sure you have a suitable number of positive and
negative examples and make a split between training examples, and examples for
testing the decision tree once it has been learned. To be objective, you might choose the
split with a random number technique.
Write a program to extract features from each character. These can start with the
histogram counts, but can be as simple as 'there are at least n black pixels in this
section' to sophisticated features to do with connected sets of black pixels. Try to
include many features, but beware of the overfitting problem – picking useless
features that will confuse the decision tree algorithm. Each feature will have either a
small number of possible values (e.g. yes/no, small/medium/large) or it can be an integer.
Consult the documentation for C5.0 for details. The output of this program will be a list
of attribute value sets, ready for input to C5.0.
Extract a decision tree from your training data using C5.0. Consult the program's
documentation and run the samples provided to get a feel for it. Use a final decision of
yes or no.
Test your tree by running the manual tester, or by writing a small program to read in
and run the rules produced by C5.0. Again consult the documentation for details.
Deliverables
Your original grid with handwritten characters.
Your program code to extract characters from the grid.
Your program code to produce features for each character.
The data input to C5.0.
The output (as a decision tree) of C5.0, running on your character feature data.
The results of running the decision tree on test characters, both positive and negative.
Due Date
Monday, April 19th.