Propose an algorithm for finding the nearest neighbor of a point given a kd-tree.
Due: at the beginning of the lecture on Tuesday, March 8.
Problem 1 In this problem, you will use the WEKA system to analyze two data sets. You will apply three learning algorithms to each data set and compare their performance.
These instructions will describe how to apply the learning algorithms to a data set. Please refer to WEKA Explorer user guide for more information.
When you start up Weka, click on the Explorer button in the WEKA GUI Chooser. This opens a large panel with several tabs, and the Preprocess tab will already be selected.
Click on "Open file...", and then select the data file you want to use (an .arff file). The Explorer window should now show number of instances, number of attributes, a list of attributes. Click on different attributes from the list on the left and see the corresponding table and the bar plot on the right-hand side of the window. You need to understand what they mean.
Now click on the "Classify" tab of the Explorer window and examine the "Test options" panel. For this assignment we will use two test options: use training set and percentage split.
Now we need to select the learning algorithm to apply. Go to the "Classifier" panel (near the top) which initially shows two buttons: "Choose" and "ZeroR". (ZeroR is a very simple rule-learning algorithm.) The general idea of this user interface is that if you click on "Choose" you can choose a different algorithm. If you click on "ZeroR" (or whatever algorithm name is displayed there), you can set the parameters for the algorithm.
Click on "Choose", and you will see a hierarchical display whose top level is "weka", whose second level is "classifiers", and whose third level contains seven general kinds of classifiers: "bayes", "functions", "lazy", "meta", "misc", "trees", "rules". To choose NaiveBayesSimple, click on the "bayes" indicator and then select "NaiveBayesSimple". To select 1R, choose "rules" and then "OneR". The process for selecting LMS is a bit more complex. First, choose "meta" and then "ClassificationViaRegression". This is a "meta-level" classifier that converts a classification problem into a regression problem. Now we must tell it which regression algorithm to employ. Click on "ClassificationViaRegression" and you will see two entries "classifier" and "debug". The "classifier" entry has two buttons: "Choose" and "M5P -M 4.0". This is where the regression algorithm is chosen. Select "Choose", then "functions", then "LinearRegression". Back at the "classifier" entry, now click on "LinearRegression", and you will see a GenericObjectEditor with four options. For "attributeSelectionMethod" select "No attribute selection". For "eliminateColinearAttributes" select "False". Now click "OK" twice, and we are ready to run the classifier.
Now we are ready to run the algorithm. Click on the "Start" button, and the Classifier Output window will show the output from the classifier. For Naive Bayes, this output consists of several sections:
Problem 3
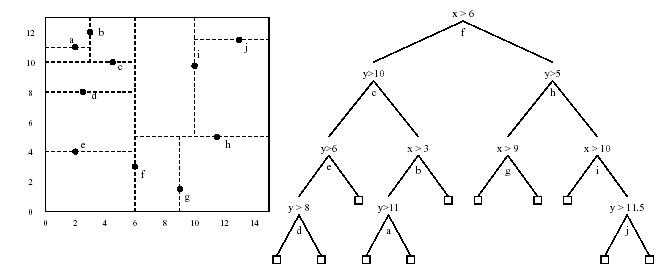
To reduce the cost of nearest neighbor algorithm a data structure
called kd-tree may be used. A kd-tree is similar to a decision tree,
except that we split using the median value along the dimension having
the highest variance, and points are stored in every internal node
(the leaves are empty).
The following figure shows an example of kd-tree and how it splits
the x,y plane.
Propose an algorithm for finding the nearest neighbor of a point
given a kd-tree.